Recently, while I was looking at DatabaseLog table in
AdventureWorks database, I found something wired. Before going further, let us
look at some important information about this table. I publish only the information
of my concern.
When I analyzed the data further I found that rows with DatabaseLog ID 5 & 6 are relatively smaller than 3 and 21 and 23 are extremely smaller. So my suspicion turned into another area. Is it because of the size the rows are stored in different pages?

The select statement showed that the data is stored in to the first available space.
Hope you fine this post interesting.
First of all, this table does not have a clustered index. It
has DatabaseLogID which is an identity column which is also the primary key,
non-clustered. The next point is that it has variable length columns. The wired thing came, when I executed SELCT *
from DatabaseLog statement.
To my surprise, the data didn’t come in ascending order of databaseLogID. In fact it has no order. This wake my curiosity and I started digging further.

Even though DatabaseLogID has identity property set to true, it does not prevent the data to be inserted in that order. So to validate the test, I got the script generated from the table. SQL Server Management studio (from 2008) has a facility where both the schema and data could be scripted. (If you are not sure of the facility, please refer this blog http://blogs.msdn.com/b/davidlean/archive/2009/09/20/tip-ssms-script-your-entire-table-including-the-data-a-hidden-gem.aspx) I used the facility to get the data as well as schema.
Now I am clear that data was inserted in the order I am retrieving, my next thought went on how the data is stored. I suspected that the data is stored in a different order. As you know, each row in the disk could be identified in the format of (file id) : (page id) : (row id). But do we really have a mechanism to know that.
And this is the results I got:

SET QUOTED_IDENTIFIER, ANSI_NULLS ON
GO
CREATE TABLE dbo.DatabaseLog(
DatabaseLogID int IDENTITY(1,1) NOT NULL,
PostTime datetime NOT NULL,
DatabaseUser sysname NOT NULL,
Event sysname
NOT NULL,
Schema sysname
NULL,
Object sysname
NULL,
TSQL nvarchar(max) NOT NULL,
XmlEvent xml NOT NULL,
CONSTRAINT PK_DatabaseLog_DatabaseLogID PRIMARY
KEY NONCLUSTERED
(
DatabaseLogID ASC
)
To my surprise, the data didn’t come in ascending order of databaseLogID. In fact it has no order. This wake my curiosity and I started digging further.

When the table does not have a clustered index, the table is considered a heap. It is not just the name. Consider a heap of stones stored along the roadside for some repair. There is no order, and any stone can be considered as the first. In database world, heap table also considered as the same.
But my question was different. Okay, there is no order, but I am getting the results in some order. Not the primary key order, but some other order. What is that order?
Even though DatabaseLogID has identity property set to true, it does not prevent the data to be inserted in that order. So to validate the test, I got the script generated from the table. SQL Server Management studio (from 2008) has a facility where both the schema and data could be scripted. (If you are not sure of the facility, please refer this blog http://blogs.msdn.com/b/davidlean/archive/2009/09/20/tip-ssms-script-your-entire-table-including-the-data-a-hidden-gem.aspx) I used the facility to get the data as well as schema.
Interestingly, in that script data came in Primary key order. (I wanted to check how it generated the script, but, even if I findout, it is not going to give me a clue on how the order got changed for me). Then I renamed to database name and placed into another database and executed the script. Again to my surprise the data came in same order.
Now I am clear that data was inserted in the order I am retrieving, my next thought went on how the data is stored. I suspected that the data is stored in a different order. As you know, each row in the disk could be identified in the format of (file id) : (page id) : (row id). But do we really have a mechanism to know that.
SQL Server has a couple of internal mechanisms, to identify rows. My friend and coworker Susantha Bathige (Blog: http://sqlservertorque.blogspot.com, twitter: @sbathige) almost an year ago showed me a function. With some search and research, I was able to identify some other functions too.
- %%lockres%% - a unique key used to identify row. This is used mainly for locks. In heaps it will display in file id : page id ; row id format. In Clustered tables it will be a key hash value of the row.
- %%physloc%% - identifies the physical location of the row. This key is used in indexes too. Unformatunately, it is in binary (6) format, which is not a human friendly format.
- sys.fn_PhysLocFormatter This is used to convert the %%physloc%% value into readable format. It will be similar to %%lockres%% for heaps except the formatting function places the value within parenthesis.
So I used all above and ran a query against DatabaseLog table.
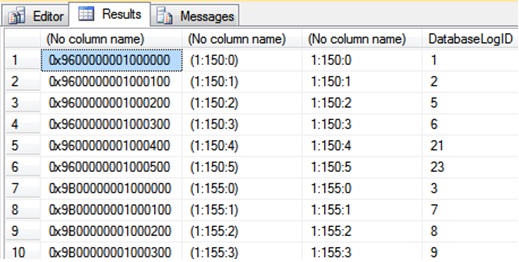
select top 10 %%physloc%%, sys.fn_PhysLocFormatter(%%physloc%%), %%lockres%%, * from DatabaseLog
And this is the results I got:

The results confirmed my suspicion. The data is stored in
different order. When retrieving, the
data comes in the order of saving as I have not placed any ORDER BY clause.
Another question came.
Okay, This sounds like a joke I heard some time back. A police officer
stopped a person and asked him: “Where is your house?” The person answered, “My house is next to
David’s house”. Now, the police officer
was not sure which David he refers to and asked him again, “Where is David’s house?” Without blinking the eye, the answer came: “before
my house”. No I know that the data is retrieved in the order it is being saved but
in what order it saves?
When I analyzed the data further I found that rows with DatabaseLog ID 5 & 6 are relatively smaller than 3 and 21 and 23 are extremely smaller. So my suspicion turned into another area. Is it because of the size the rows are stored in different pages?
I created another script to confirm my thoughts.
CREATE TABLE dbo.MyHeapLog
(MyHeapLogID INT NOT NULL IDENTITY(1,1) PRIMARY KEY NONCLUSTERED,
MyHeapLogdata VARCHAR(8000) NULL
)
GO
INSERT INTO dbo.MyHeapLog VALUES(REPLICATE('a', 2000))
GO
INSERT INTO dbo.MyHeapLog VALUES(REPLICATE('b', 2000))
GO
INSERT INTO dbo.MyHeapLog VALUES(REPLICATE('c', 5000))
GO
INSERT INTO dbo.MyHeapLog VALUES(REPLICATE('d', 1000))
GO
select %%physloc%%, sys.fn_PhysLocFormatter(%%physloc%%), %%lockres%%, * from dbo.MyHeapLog
GO
Since the first two rows will take approximately 4000 bytes,
the third row needs to go to a new page.
The forth row is smaller, which could fit into both first page as well
as second page. Where will it go?

The select statement showed that the data is stored in to the first available space.
Now the next question:
How it identifies the available space? Well, I am still researching on it. My initial tests showed that they generally have the almost same amount of reads and writes of clustered tables. But I see more CPU usage when it comes to heap table inserts.
Hope you fine this post interesting.
No comments:
Post a Comment